
L’objectif de ce tutoriel est de vous montrer comment utiliser Flume et Hive pour analyser des données en provenance de Twitter.
Il a également pour objectif de mettre en évidence les difficultés que l’on rencontre actuellement avec des plateformes Big Data en évolution rapide mais pas toujours stabilisées, d’où l’importance de disposer d’une expertise suffisante dans le domaine.
Ce tutoriel a été élaboré à partir de la version sandbox 2.1 de la distribution Hortonworks.
Présentation de Flume
Flume a été initialement développé par Cloudera avant d’être reversé à la communauté Apache. Il porte maintenant l’appellation Flume NG (Next Génération). C’est un outil relativement simple faisant aujourd’hui parti de l’éco-système Hadoop.
Flume fonctionne comme un service distribué pour assurer la collecte de données en temps réel, leur stockage temporaire et leur diffusion vers une cible.
![]()
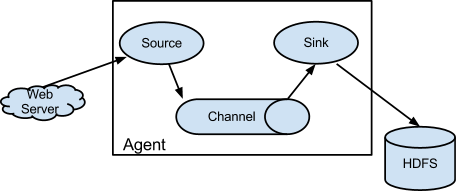
Techniquement, un agent Flume permet de créer des routes pour relier une source à une cible via un canal d’échange.
La « source » Flume a pour pour but de récupérer les messages à partir de différentes sources, en particulier des fichiers de logs mais aussi comme nous le verrons des données Twitter.
Le « canal » Flume est une zone tampon qui permet de stocker les messages avant qu’ils soient consommés. On utilise généralement un stockage en mémoire.
Le « cible » Flume consomme par lot les messages en provenance du « canal » pour les écrire sur une destination comme HDFS par exemple.
Lorsque la vitesse d’intégration des nouveaux messages est plus rapide que celle d’écriture vers la cible, la taille du « canal » augmente afin de garantir qu’aucun message ne soit perdu.
Installation de Flume
On se connecte tout d’abord à la machine virtuelle à partir d’un terminal distant:
ssh root@127.0.0.1 -p 2222
Puis on installe le package via la commande:
yum install -y flume
Le package s’installe et à la fin, votre écran devrait ressembler à ceci.

Configuration pour accéder à Twitter
Vous devez tout d’abord créer une application Twitter en allant sur le site des développeurs Twitter (https://dev.twitter.com/apps/) afin de générer vos identifiants.

Avec ces identifiants, on va pouvoir mettre à jour le fichier de configuration flume.conf.

Outre les identifiants Twitter, on va mettre à jour le paramètre keywords pour filtrer les tweets sur les éléments qui nous intéressent (dans mon exemple, je m’intéresse aux tweets sur le big data).
On remarque que tous les paramètres sont préfixés par le nom de l’agent, ici TwitterAgent.
On va également préciser l’emplacement HDFS où seront stockés les tweets récupérés.
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://sandbox.hortonworks.com:8020/user/hue/twitter/tweets
Vous trouverez une information plus exhaustive du paramétrage sur http://flume.apache.org.
Si vous avez modifié le fichier sur votre machine, il ne reste plus qu’à le copier sur la VM.
scp -P 2222 flume.conf root@127.0.0.1:/etc/flume/conf/
Il faut maintenant télécharger flume-sources-1.0-SNAPSHOT.jar. Ce package contient les fonctions nécessaires pour accéder et récupérer les données de Twitter.
On va également le copier sur la VM, dans le répertoire des fichiers jars de Flume.
scp -P 2222 flume-sources-1.0-SNAPSHOT.jar root@127.0.0.1:/usr/lib/flume/lib/
J'ai rencontré pas mal de soucis pour savoir où positionner ce fichier. J'ai essayé différentes configurations mais sans succès. Plusieurs blogs conseillaient de simplement le copier puis d'indiquer son emplacement dans le fichier flume-env.sh mais cela n'a jamais fonctionné chez moi.
Démarrer Flume
On démarre flume avec la commande suivante:
flume-ng agent -c /etc/flume/conf -f /etc/flume/conf/flume.conf -n TwitterAgent > twitter.log
On précise le répertoire et le fichier de configuration de Flume. On indique également l’agent que l’on démarre, ici TwitterAgent. On redirige la sortie dans un fichier pour analyse si besoin.
De mon côté, je préfère lancer cette commande via un script flume.sh dans lequel j’ai simplement reporté cette ligne.
Au bout de quelques secondes (minutes) en fonction de vos recherches, les données de tweets apparaissent sous HDFS.

Si on sélectionne un fichier, on peut visualiser les données transmises dans les tweets.
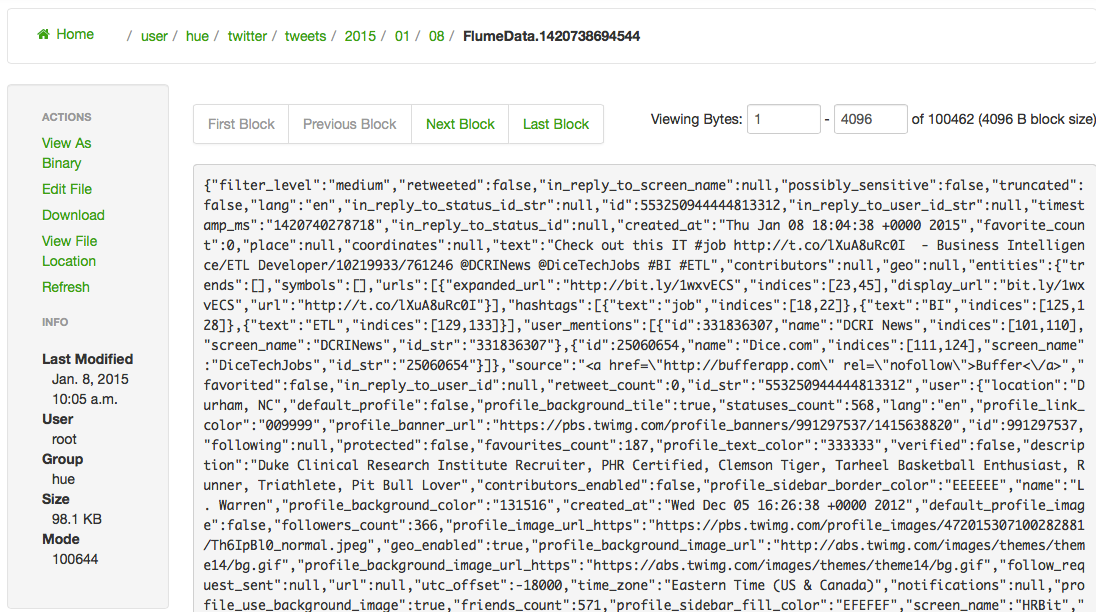
Analyser les données avec Hive
Twitter fournit des données au format JSON. Or Hive ne sait pas les traiter nativement. Il faut donc récupérer une librairie java qui va permettre à l’outil Hive de travailler avec ce format spécifique.
Plusieurs blogs conseillaient d’utiliser le fichier suivant:
json-serde-1.1.6-SNAPSHOT-jar-with-dependencies.jar
Mais cela n’a jamais fonctionné chez moi comme pour de nombreux lecteurs dans la même situation. Je pense que l’extrême évolutivité des distributions Hadoop rend complexe la mise au point de tutoriaux qui restent valides dans le temps. Et ce post n’y échappera pas 🙂
Là encore, après de multiples recherches et tentatives, j’ai finalement trouvé une solution en récupérant la dernière version de ce fichier sur https://github.com/rcongiu/Hive-JSON-Serde. Je n’ai pas pris les sources mais directement le binaire suivant:
http://www.congiu.net/hive-json-serde/1.3/cdh5/ json-serde-1.3-jar-with-dependencies.jar
J’ai simplement copié ce fichier sur /root/.
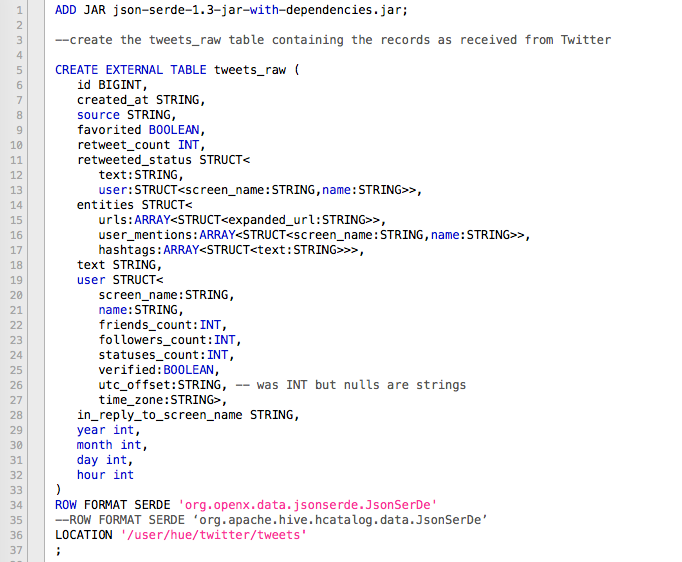
On va ensuite créer une table Hive. Une table externe car nous n’avons pas besoin de déplacer physiquement les données. Celles-ci resteront toujours sur HDFS et ne seront pas dupliquées.
On n’oublie pas au début du script de rajouter en début de script une commande pour prendre en compte la librairie java évoquée ci-dessus.
Il suffit ensuite de lancer le fichier via la commande suivante:
hive -f tweet_raw.sql

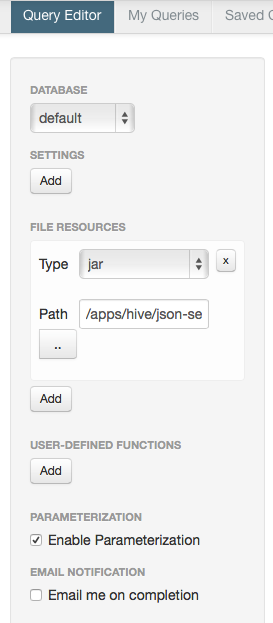
Si l’on veut utiliser l’interface web Hue pour visualiser la table, il faut au préalable copier le fichier jar json sur /apps/hive puis le charger dans l’interface en rajoutant ce fichier jar comme un fichier de ressource dans l’onglet Query Editor (Beewax).
On peut ensuite visualiser la table dans l’interface Hue directement.
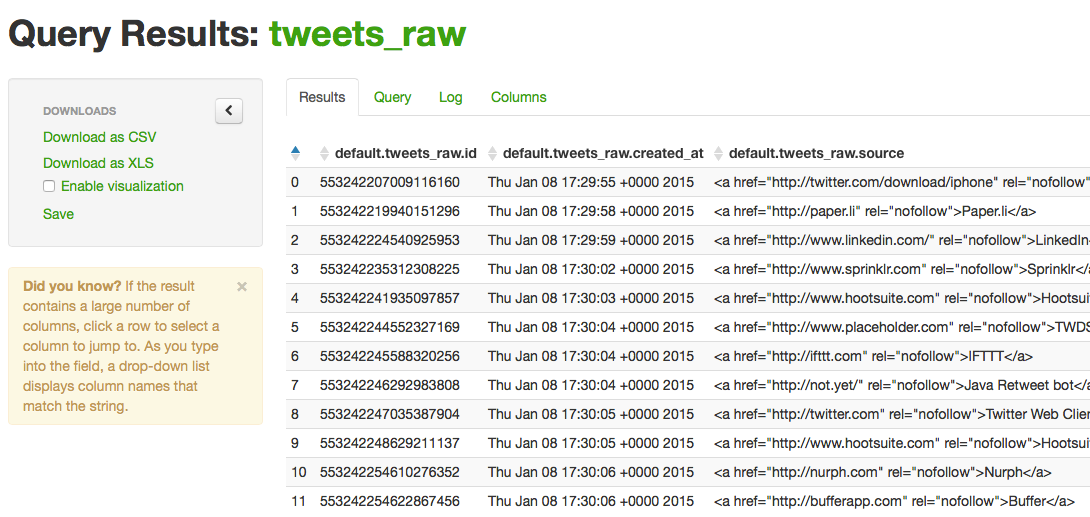
On peut évidemment faire des requêtes.
Pour illustrer ce point, je vais classer les utilisateurs de tweets par ordre décroissant en fonction du nombre de followers. A noter l’accès au champ followers_count qui n’est pas un champs simple de la table mais un champs inclus dans une structure.
select user.screen_name, user.followers_count c from tweets_raw order by c desc
Et voici le résultat:
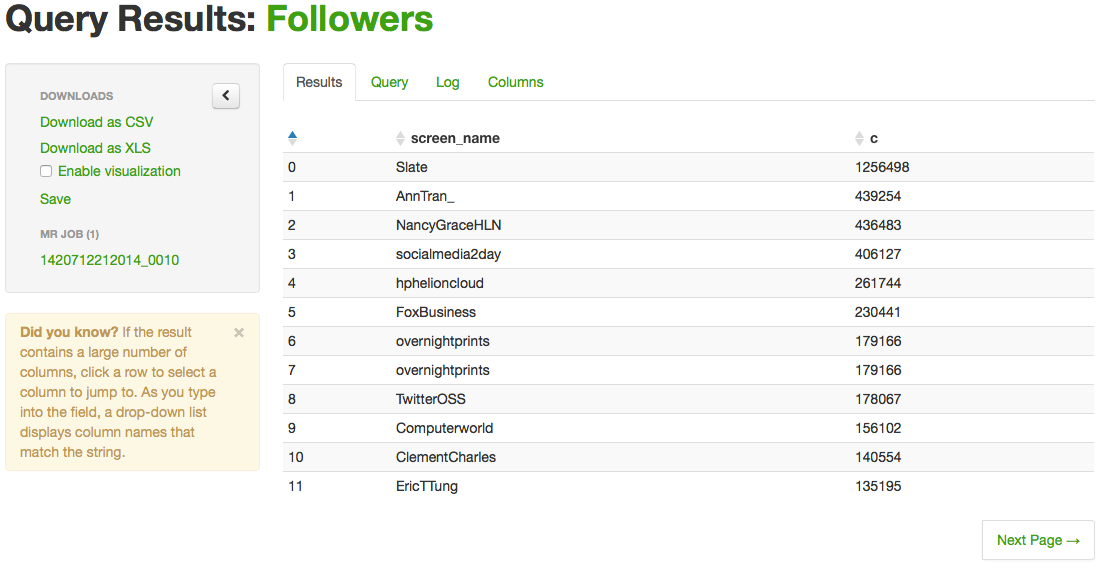
Merci de m’avoir suivi et a bientôt pour un tutoriel sur la visualisation des données analysées de Twitter avec Qlik.